
本記事は以下の動画で必要なTesseract・poppler・7zipのダウンロード方法について解説します。
動画の内容はPythonとTesseract OCRを使って、PDF(スキャンデータ)から会社名を抽出し、その値を利用して会社ごとのPDFファイルを作成するという内容になっています。
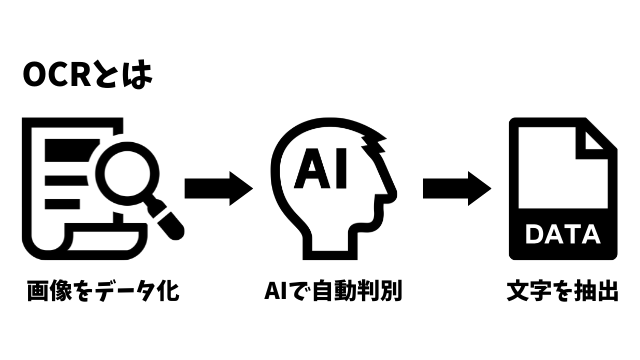
OCR(光学的文字認識)とは下の画像のように、手書きや印刷された文字をイメージスキャナやデジタルカメラによって読みとり、コンピュータが利用できるデジタルの文字コードに変換する技術です。
PythonはTesseractというOCRエンジンを使うことができるため、これを用いて資料の文字データを抽出します。(Tesseractは無料で使用することができます。)
Tesseractのインストール
まず始めにTesseractをダウンロードします。
https://github.com/UB-Mannheim/tesseract/wiki
お使いのパソコンによって32bitまたは64bit版をダウンロードしてください。
言語を選択して次に進みます。
次へ。
ライセンスを確認して次へ。
今回は自分しか使わないので、Install just for meを選択します。
Additional script dataを展開します。
2つにチェックを入れます。
次に、Additional language dataを展開します。
2つにチェックを入れて次に進みます。
インストールする場所を選択します。
そのままインストールを選択します。
インストールが開始されます。
終了したら次に進みます。
これでTesseractのインストールが完了です。
popplerのインストール
TesseractはPDFを文字認識することができないため、PDFファイルを一度画像ファイルに変換します。(最後にPDFファイルに戻す。)
画像の変換にはpdf2imageを使用しますが、popplerというコマンドラインツールをインストールする必要があります。
現在、popplerがダウンロードできたサイトが閉鎖されています。(代替案の執筆は少々お待ちください。)
任意のpopplerダウンロードします。
zip形式で圧縮されているため、解凍してください。
7zipというソフトを使って解凍することができます。
https://sevenzip.osdn.jp/download.html
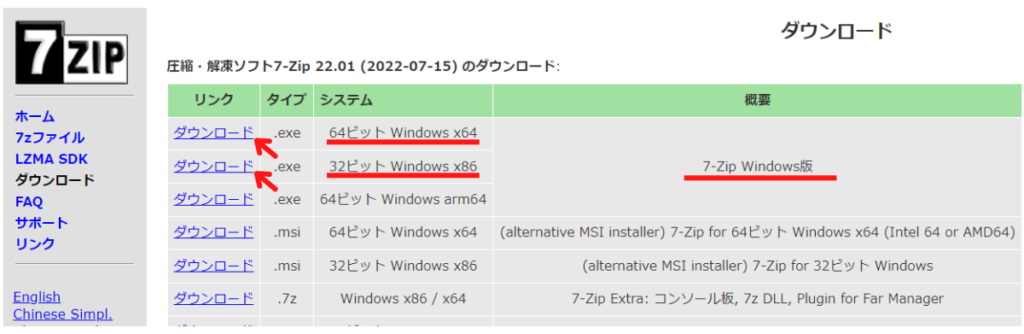
ダウンロードが完了すると、ファイルを右クリックで7z形式の解凍ができるようになっています。
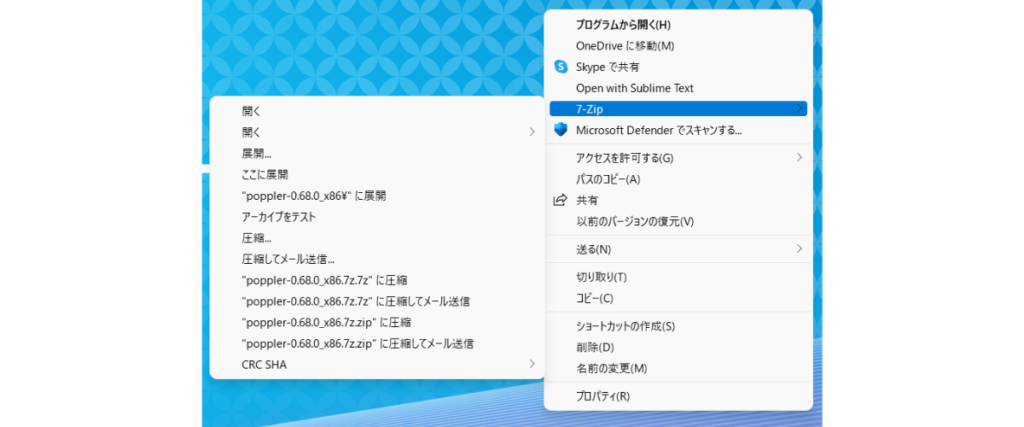
解凍すると4つのファイルがあります。

ディレクトリ(フォルダ)構造が下記になるように移動します。
これでpopplerのインストールが完了です。
おわりに
Pythonを使った社内DXの一例を紹介しました。
他にできることはこちらの動画にまとめていますので、興味のある方は是非ご確認ください。
関連記事
【Python】Ghostscriptを使ってPDFファイルを簡単に圧縮する方法
Python 基礎文法の教科書を執筆しました!

コメント